LatestTOP
- Kun Ma, Bo Yang, Jin Zhou, Yongzheng Lin, Kun Zhang, Ziqiang Yu, Outcome-based School-Enterprise Cooperative Software Engineering Training, Proceedings of 2018 ACM Turing Celebration Conference China (TURC 2018), Shanghai, China, May 19-20, 2018, 15-20 (计算机教育顶级会议,中国图灵大会。该论文被教育部高等学校计算机类专业教学指导委员会评为“第二届全国高等学校计算机教育教学青年教师优秀论文奖二等奖”。)
- 马坤,蔺永政,韩士元,周劲,董吉文,杨波, "成果为导向多方共赢的校企协同创新创业实践方法与课程体系建设," 计算机教育, 2019, 21 (7): 102-106 (计算领域高质量科技期刊T2/CCF C类,本期封面文章,该论文被教育部高等学校计算机类专业教学指导委员会评为“2019-2020全国计算机教育优秀论文一等奖【本期参评的1006篇论文仅评选出3个一等奖】”。)
- Kun Ma, Nan Zheng, Shan Jing, Zhenxiang Chen, Bo Yang, "TELF-PSPOC: Three-layer Ensemble Learning Framework for Predicting Student Performance of Online Courses," 计算机教育, 2022, 20 (12): 85-95(计算领域高质量科技期刊T2/CCF C类)
- Kun Ma, Yongwei Shao, Jiaxuan Zhang, Zhenxiang Chen, Bo Yang, "ELM-EDP: Ensemble Learning Model FOR Early Dropout," 计算机教育, 2023, 21 (12): 124-139 (计算领域高质量科技期刊T2/CCF C类)
- Kun Ma, Bo Yang, Kun Liu, Automated Grading of Collaborative Software Engineering Training with Cloud Distributing Scripts, Proceedings of 2019 ACM Turing Celebration Conference China (TURC 2019), Chengdu, China, May 17-19, 2019, No. 84(计算机教育顶级会议,中国图灵大会。)
- Kun Ma, Kun Liu, and Lixin Du, Automated Assessment and Evaluation of Contribution of Collaborative Software Engineering Development Process, Proceedings of the 2020 27th Asia-Pacific Software Engineering Conference (APSEC 2020), Singapore, Singapore, Dec. 1-4, 2020, 500-504 (CCF C类会议)
- Jiaxuan Zhang, Kun Ma*, EDPS: Early Dropout Prediction System of MOOC Courses, Proceedings of the 2022 29th Asia-Pacific Software Engineering Conference (APSEC 2022), Online, Dec. 6-9, 2022, 562-563 (CCF C类会议)
- Kun Ma, Ajith Abraham, Bo Yang, and Runyuan Sun, Intelligent Web Data Management: Software Architectures and Emerging Technologies, Springer International Publishing, Switzerland, ISBN-13: 978-3-319-30191-4, 162 pages, 2016.
- Xinyu Liu, Kun Ma*, Qiang Wei, Ke Ji, Bo Yang, and Ajith Abraham, "G-HFIN: Graph-based Hierarchical Feature Integration Network for Propaganda Detection of We-media News Articles," Engineering Applications of Artificial Intelligence, 2024, 132 (6): 1-16 (EI: , WOS: IF: 7.802, CCF C类, Q2, Top期刊)
- Qiang Wei, Kun Ma*, Xinyu Liu, Ke Ji, Bo Yang, and Ajith Abraham, "DIMN: Dual Integrated Matching Network for Multi-Choice Reading Comprehension," Engineering Applications of Artificial Intelligence, 2024, 130 (4): 1-11 (EI: , WOS: IF: 7.802, CCF C类, Q2, Top期刊)
- Benkuan Cui, Kun Ma*, Leping Li, Weijuan Zhang, Ke Ji, Zhenxiang Chen, Ajith Abraham, "Intra-graph and Inter-graph Joint Information Propagation Network with Third-order Text Graph Tensor for Fake News Detection," Applied Intelligence, 2023, 53 (16): 18971–18988(IF: 5.019, CCF C类, Q2)
- Kun Ma, Changhao Tang, Weijuan Zhang, Benkuan Cui, Ke Ji, Zhenxiang Chen, Ajith Abraham, "DC-CNN: Dual-channel Convolutional Neural Networks with Attention-pooling for Fake News Detection," Applied Intelligence, 2023, 53 (7): 8354–8369 (WOS: 000834007100001, IF: 5.019, CCF C类, Q2)
- Changhao Tang, Kun Ma, Benkuan Cui, Ke Ji, Ajith Abraham, "Long Text Feature Extraction Network with Data Augmentation," Applied Intelligence, 2022, 52 (12): 17652–17667 (IF: 5.019, CCF C类, Q2)
- Zhihao Hou, Kun Ma*, Yufeng Wang, Jia Yu, Ke Ji, Zhenxiang Chen, and Ajith Abraham, "Attention-based learning of self-media data for marketing intention detection," Engineering Applications of Artificial Intelligence, 2021, 98 (2): 104118: 1-9 (IF: 7.802, CCF C类, Q1)
- Yufeng Wang, Kun Ma*, Laura Garcia-Hernandez, Jing Chen, Zhihao Hou, Ke Ji, Zhenxiang Chen, Ajith Abraham, "A CLSTM-TMN for Marketing Intention Detection," Engineering Applications of Artificial Intelligence, 2020, 91 (5): 1-9 (IF: 6.212, CCF C类, Q1)
- Ziqiang Yu, Ajith Abraham, Xiaohui Yu, Yang Liu, Kun Ma*, Jing Zhou, "Improving the effectiveness of keyword search in databases using query logs," Engineering Applications of Artificial Intelligence, 2019, 81 (5): 169-179 (IF: 4.201, CCF C类, Q1)
- Kun Ma, Bo Yang, Zhe Yang, and Ziqiang Yu, "Segment Access-aware Dynamic Semantic Cache in Cloud Computing Environment," Journal of Parallel and Distributed Computing, 2017, 110 (12): 42-51(IF: 1.815, CCF B类)
- Ma, K. and Yang, B., "Large-scale Schema-free Data Deduplication Approach with Adaptive Sliding Window using MapReduce," The Computer Journal, 2015, 58 (11): 3187-3201 (IF:1, CCF B类)
- Jing Chen, Kun Ma, Ke Ji, Zhenxiang Chen, "TM-HOL: Topic Memory model for Detection of Hate Speech and Offensive Language," Concurrency and Computation: Practice and Experience, 2021, Online (): e6754 (WOS: , IF: 1.536, EI: , CCF C类)
- Kun Ma, Ziqiang Yu, Ke Ji, and Bo Yang, "Stream-Based Live Public Opinion Monitoring Approach with Adaptive Probabilistic Topic Model," Soft Computing, 2019, 23 (16): 7451-7470(IF: 2.04, CCF C类, Q3)
- Kun Ma, Bo Yang, and Ziqiang Yu, "Optimization of Stream-based Live Data Migration Strategy in the Cloud," Concurrency and Computation: Practice and Experience, 2018, 30 (12): e4293: 1-18 (IF: 1.114, CCF C类)
- Ma, K. and Yang, B., "Stream-based Live Data Replication Approach of In-memory Cache," Concurrency and Computation: Practice and Experience, 2017, 29 (11): e4052: 1-9 (IF: 1.133, CCF C类)
- Ziqiang Yu, Fatos Xhafa, Yuehui Chen, Kun Ma, "A Distributed Hybrid Index for Processing Continuous Range Queries over Moving Objects," Soft Computing, 2019, 23 (9): 3191–3205 (IF: 2.367, CCF C类, Q3)
- Ziqiang Yu, Yuehui Chen, Kun Ma*, "Real-time processing of k-NN queries over moving objects," Soft Computing, 2017, 21 (18): 5181-5191 (IF: 2.472, CCF C类)
- Ke Ji, Zhenxiang Chen, Runyuan Sun, Kun Ma, Zhongjie Yuan, Guandong Xu, "GIST: A Generative Model with Individual and Subgroup-based Topics For Group Recommendation," Expert Systems with Applications, 2018, 94: 81-93 (IF: 3.928, CCF C类, Q2)
- Yue Lu, Kun Ma and Jidong Duan, Influence Model of Paper Citation Networks with Integrated Weighted PageRank and HITS, Proceedings of the 2021 IEEE 24th International Conference on Computer Supported Cooperative Work in Design (CSCWD 2021), Dalian, May 5-7, 2021, 1081-1086 (CCF C)
- Xiaoqian Zhang and Kun Ma*, Toward Sliding Time Window of Low Watermark to Detect Delayed Stream Arrival, Proceedings of the 2020 16th EAI International Conference on Collaborative Computing: Networking, Applications and Worksharing (CollaborateCom 2020), Part of the Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering book series (LNICST, volume 350), Shanghai, China, Oct. 16-18, 2020, 444-454 (CCF C)
- Kun Ma, Kun Liu, and Lixin Du, Automated Assessment and Evaluation of Contribution of Collaborative Software Engineering Development Process, Proceedings of the 2020 27th Asia-Pacific Software Engineering Conference (APSEC 2020), Singapore, Singapore, Dec. 1-4, 2020, 500-504 (CCF C)
- Fanghan Liu, Wenzheng Cai, and Kun Ma*, PLRS: Personalized literature hybrid recommendation system with paper influence, Proceedings of the 2020 20th International Conference, ICA3PP 2020, New York City, NY, USA, October 2–4, 2020, Proceedings, Part III, Lecture Notes in Computer Science 12454, New York, USA, Oct. 2-4, 2020, 703-705 (CCF C)
- Yinnan Yao, Nan Su, Kun Ma*, UJNLP at SemEval-2020 Task 12: Detecting Offensive Language Using Bidirectional Transformers, Proceedings of the 2020 14th International Workshop on Semantic Evaluation (SemEval 2020), Barcelona, Spain, Dec. 12-13, 2020, 2203–2208 (Importance of papers in SemEval conference is just below 3 top NLP conferences (ACL/EMNLP/NAACL) in the field of Computational Linguistics.)
- Yinnan Yao, Xiunan Zheng, and Kun Ma*, ILFS: Intelligent Lost and Found System using Multidimensional Matching Model, Proceedings of 2019 IEEE International Conference on Ubiquitous Intelligence & Computing (UIC 2019), Leicester, UK, August 19-23, 2019, 1205-1208 (CCF C类)
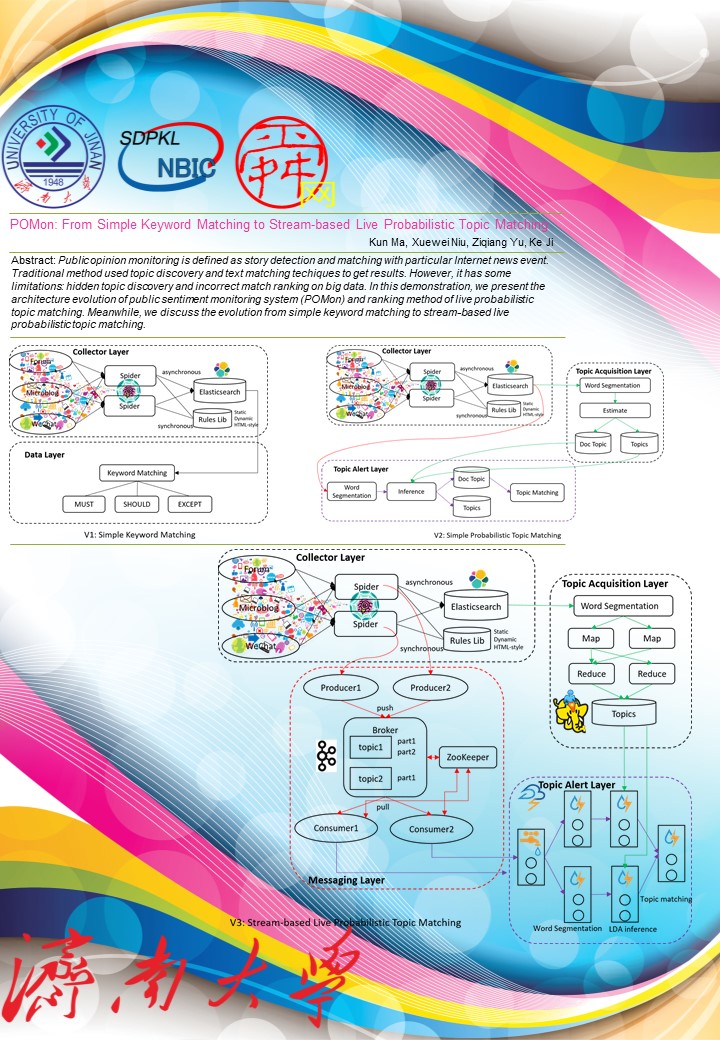
- Kun Ma, Xuewei Niu, Ziqiang Yu, Ke Ji, POMon: From Simple Keyword Matching to Stream-based Live Probabilistic Topic Matching, Proceedings of 2018 IEEE Ubiquitous Intelligence & Computing (UIC 2018), Guangzhou, China, Oct. 8-12, 2018, 1189-1192 (CCF C类)
- Xuewei Niu, Kun Ma*, Toward An Efficient Cache Management Framework, Proceedings of 2018 IEEE Ubiquitous Intelligence & Computing (UIC 2018), Guangzhou, China, Oct. 8-12, 2018, 1491-1496 (CCF C类)
- Kun Ma, Ziqiang Yu, Ke Ji, Bo Yang, Stream-based Live Probabilistic Topic Computing and Matching, Proceedings of the 17th International Conference on Algorithms and Architectures for Parallel Processing (ICA3PP 2017), Part II, Lecture Notes in Computer Science, 10393, Helsinki, Finland, Aug. 21-23, 2017, 397-406 (CCF C类)
- Kun Ma, Shuhui Liu, Yongzheng Lin, Ziqiang Yu, Ke Ji, Parallel Grouping Particle Swarm Optimization with Stream Processing Paradigm, Proceedings of 2017 IEEE 19th International Conference on High Performance Computing and Communications Workshops (HPCCWS 17) in conjunction with the 19th IEEE International Conference on High Performance Computing And Communications (HPCC 17), Bangkok, Thailand, Dec. 18-20, 2017, 22-26 (CCF C类)
- Kun Ma, Xuewei Niu, Ziqiang Yu, Ke Ji, POMon: From Simple Keyword Matching to Stream-based Live Probabilistic Topic Matching, Proceedings of 2018 IEEE Ubiquitous Intelligence & Computing (UIC 2018), Guangzhou, China, Oct. 8-12, 2018, 1189-1192 (CCF C类)
- Ma, K., Tang, Z., Zhong, J., Yang, B., LPSMon: A Stream-based Live Public Sentiment Monitoring System, Proceedings of The 17th International Conference on Web-Age Information Management, Part II, Lecture Notes in Computer Science , Nanchang, China, June 3-5, 2016, 9659: 534-536 (CCF C类)
- Ma, K., Yang, B., Access-aware In-memory Data Cache Middleware for Relational Databases, Proceedings of 17th IEEE International Conference on High Performance Computing and Communications (HPCC 15), New York, USA, August 24 - 26, 2015, 1506-1511 (CCF C类)
- Ma, K., Yang, B., and Chen, G., DOI Proxy Framework for Automated Entering and Validation of Scientific Papers, Proceedings of the 14th International Conference on Web-Age Information Management (WAIM 2013), Lecture Notes in Computer Science, Qinhuangdao, China, June 14-16, 2013, 2013, 7923: 799-801 (CCF C类)





{kind=link}